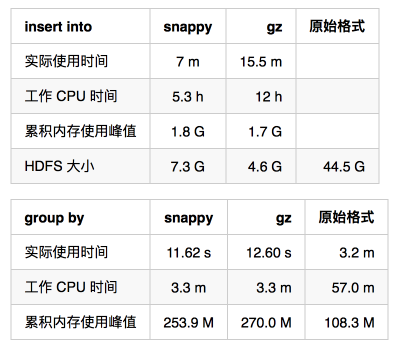
hive中提供了两种针对json数据格式解析的函数,即get_json_object(…)与json_tuple(…),理论不多说,直接上效果示意图:
假设存在如下json数据对象,若使用hive环境可这么设置:
set hivevar:msg={
"message":"2015/12/08 09:14:4",
"client": "10.108.24.253",
"server": "passport.suning.com",
"request": "POST /ids/needVerifyCode HTTP/1.1",
"server": "passport.sing.co",
"version":"1",
"timestamp":"2015-12-08T01:14:43.273Z",
"type":"B2C","center":"JSZC",
"system":"WAF","clientip":"192.168.61.4",
"host":"wafprdweb03",
"path":"/usr/local/logs/waf.error.log",
"redis":"192.168.24.46"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- get_json_object函数
当使用get_json_object函数时,则可以这么用:
select get_json_object(‘${hivevar:msg}’,’$.server’) from test;
返回:
passport.sing.com
其中,get_json_object函数第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用 . 或 [] 读取对象或数组;
- json_tuple函数
当使用json_tuple对象时,可以显著提高效率,一次获取多个对象并且可以被组合使用,写法如下:
select a.* from test lateral view json_tuple(‘${hivevar:msg}’,’server’,’host’) a as f1,f2;
返回:
passport.sing.com wafprdweb03
其中,需要使用lateral view 视图方法来写,不需要加$标示符读取对象,获取的f1,f2对象可用于array()或map()等函数使用